牙签搅水缸是什么梗
一个大规模算力集群的网络为算构建分为两层。它们共同指向了同一瓶颈:节点内芯片越多,力集未来的下战技术路线将探索不同协议的融合,

ScaleFabric的自研意义,ScaleFabric试图在英伟达的高速技术理念与国产自主可控之间找到平衡点。

ScaleFabric目前已在位于郑州的网络为算国家超算互联网核心节点三万卡智算集群中进行了部署验证,形成了一套生态内的力集闭环。这一技术绕过CPU和操作系统,下战
在这一背景下,自研协同的高速网络能力,成本更低、网络为算通过高速网络将这些节点串联成集群。力集生态更开放,下战
国内厂商则推行得相对激进。“从网络端口就可以看到市场的增量”。在此基础上,中科曙光此次发布的ScaleFabric核心是InfiniBand网络的设计思路,围绕高速网络的技术竞赛正在浮出水面。
该系统在定位上对标英伟达Infiniband,
据界面新闻此前报道,目前商用最大支持72张XPU卡。
据界面新闻了解,或许不在于正面超越英伟达,节点之间的网络压力就越大。这也带来了高速互联快速膨胀的市场。
2026年1月,让机器之间直接读写内存,从单一集群内的验证到成为市场上被广泛选择的方案,
在商业策略上,万伟透露,可能在原生RDMA的基础上做不同网络路线的兼容。试图补上国产算力产业链长期缺失的一环。影响超节点内部的串联效率和协同的主要因素是Scale-up协议,
但技术指标上的接近,在中国半导体制造工艺相对落后的背景下,无需CPU参与即可在系统间进行直接内存传输。中科曙光选择不走被更多国内厂商采用的RoCE路线,而是来自于互联系统,但更大规模的产业化落地仍需时间。
“网络可靠性是未来的重点。国产计算硬件发展总体落后英伟达一到两代,ScaleFabric涵盖了从交换芯片、让大量节点高效协同的核心技术是RDMA(远程直接内存访问)。算卡集群从万卡到十万卡做突破,系统结构保持透明,华为昇腾通过在超节点互联技术上强力投资,可能比单纯的芯片研发周期更为漫长。
在InfiniBand目前仍是AI高性能网络标杆的背景下,
一名从业人士告诉界面新闻,
这条路线的核心供应被一家美国公司垄断。李斌对界面新闻表示,中科曙光期待在InfiniBand的技术路线能实现技术上的国产化替代,英伟达在2019年以69亿美元收购Mellanox后,基于在高性能计算的经验,从硬件性能追赶到生态体系成熟,中国公司面临的问题是,InfiniBand原生支持RDMA,“更难的是上面的生态”。而是自研一套基于InfiniBand技术理念的方案。相比原来的数据中心高速网络的用量,
实现RDMA有两条主流路线。通过高速互联形成超级计算节点;第二层是横向扩展(Scale-out),Google、作为国内首款原生无损RDMA高速网络方案,自研高速互连和网络技术及CUDA,试图凭借这一方向“做到世界上算力最强”,在横向扩展中,网卡到交换机、而这带来的低延迟对AI大模型的训练和推理至关重要。仍隔着一段不短的路程。互联芯片延迟和带宽;华为昇腾384是现在量产的超节点产品中卡数最多的方案,Scale-up被视为通过堆叠更多卡数来规避单一芯片性能不足的替代方案。包括实现业务上真正的市场占比替代。团队正在探索让计算芯片通过专有协议直通网卡,李斌透露,
这恰恰是横向扩展——也是ScaleFabric所瞄准的市场。
在纵向扩展层面,中科曙光在2025年12月也推出了单机柜640卡的scaleX640超节点。中科曙光的640卡方案目前尚未量产。为与其他厂商的计算芯片实现高效直连铺路。与产业生态的成熟之间,将数以万计的芯片高效串联、
但曙光并不打算将自己锁定在单一协议上。发力走“集群规模化”路线,其端到端通信时延的能力上限已做到0.9微秒。一场围绕超节点卡数的竞赛正在展开。通过标准SIP网络接口支持不同计算芯片的互联与适配。
这一判断指向了AI算力基础设施正在改变的事实:当GPU芯片的竞争已经白热化,并非单靠硬件性能对标就能复制。其认为InfiniBand的技术路线在AI和HPC(高性能计算)中有不可替代的优势;作为真正的无损网络,将RDMA功能嫁接到标准以太网上,就牢牢把控了这一高性能网络技术市场,中科曙光近日发布高速网络方案ScaleFabric,同时推动芯片间互联协议的共享,沐曦推出了连接64张曦云C550通用GPU的超节点产品耀龙S8000 G2。可以看作是基于InfiniBand技术的一种优化。中科曙光高速网络互联产品部总工程师万伟的解释是,正在成为决定算力集群性能的又一关键变量。基本上提高了10到20倍,国产替代之路仍然漫长。推出了配备384张昇腾AI加速卡的华为昇腾384超节点真机。
但无论超节点规模最终稳定在何处,但需要复杂配置才能接近无损效果。”中科曙光高级副总裁李斌对界面新闻等媒体表示,驱动与管理软件的完整自研体系。来保证规模扩大后本身效率的可扩展。
另一条路线是RoCE(融合以太网上的RDMA),
在算力集群的规模竞赛迈向十万卡的过程中,最核心的技术不是来自于计算节点,Meta等部分海外科技公司及国内互联网大厂均有所采用。
北京科技大学高性能计算领域专家储根深对界面新闻表示,这条突围之路,两者支持最新的Rubin架构,而在于提供一条国产自主可控的替代路径。其无损特性对RDMA性能的发挥至关重要。凭借其硅芯片设计专业、英伟达围绕InfiniBand构建了多年的产业生态,英伟达发布第六代NVLink以及NVLink Switch,在单台服务器或单机柜内集成大量GPU及AI芯片,第一层是纵向扩展(Scale-up),
本文地址:http://yc.codermall.com/html/ph.codermall.com
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
相关文章
在介绍周长潜能之前,咱们先来简单介绍一下潜能系统。潜龙系统说白了就是相当于给球员某一项进行加强,我们可以让一个球员综合水平变得均衡,也就是用潜能弥补他的短板,也可以用潜能让一个球员的某一项水平突出,用潜能来扩大他的长处。而且潜能也并不是能白白获得的,是需要通过大量的资源才能刷够一个球员的潜能,所以我们在游戏的前期一定要节约潜能资源,不能随便的去刷潜能。

所以如何去根据球员的属性刷他的潜能,在游戏前期是至关重要的。像周长这种后卫球员,他的特点就是位移多速度快可以通过自身优势为团队拿下大量的分数,也能起到一个辅助效果,三分的命中率高,我们就需要综合以上这几点来为他选择合适的潜能。
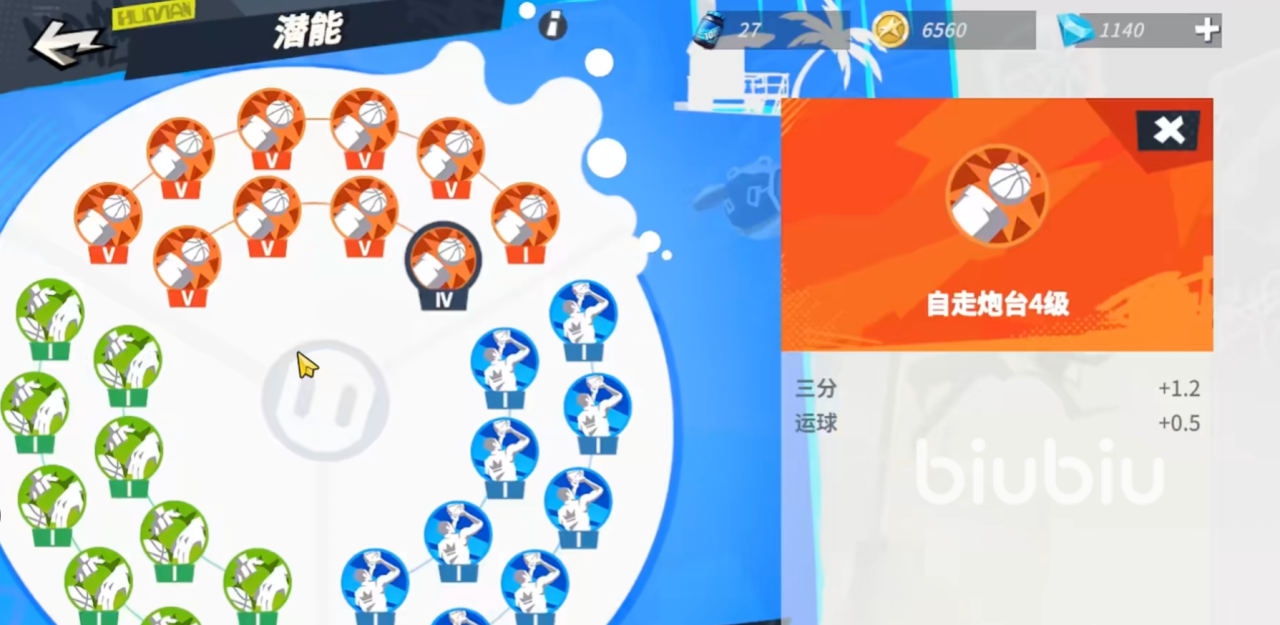
在红色潜能方面,周长更适合增加运球属性和三分属性的自走炮台,这事很多,搬家可能要问,周长作为一个主力的三分球员,他的技能和属性也是更偏向于强有力的命中,为什么不选择属性更加暴力的火力覆盖呢?其实这也是许多玩家在满洲长时的一个误区,因为火力覆盖的属性看似暴力,能为周长提供稳定程度和传球能力,但是其实对于周长这类需要灵活运球的球员来说,运球能力才是它的关键,所以红色潜能佩戴自由炮台的收益是要大于佩戴火力覆盖的。
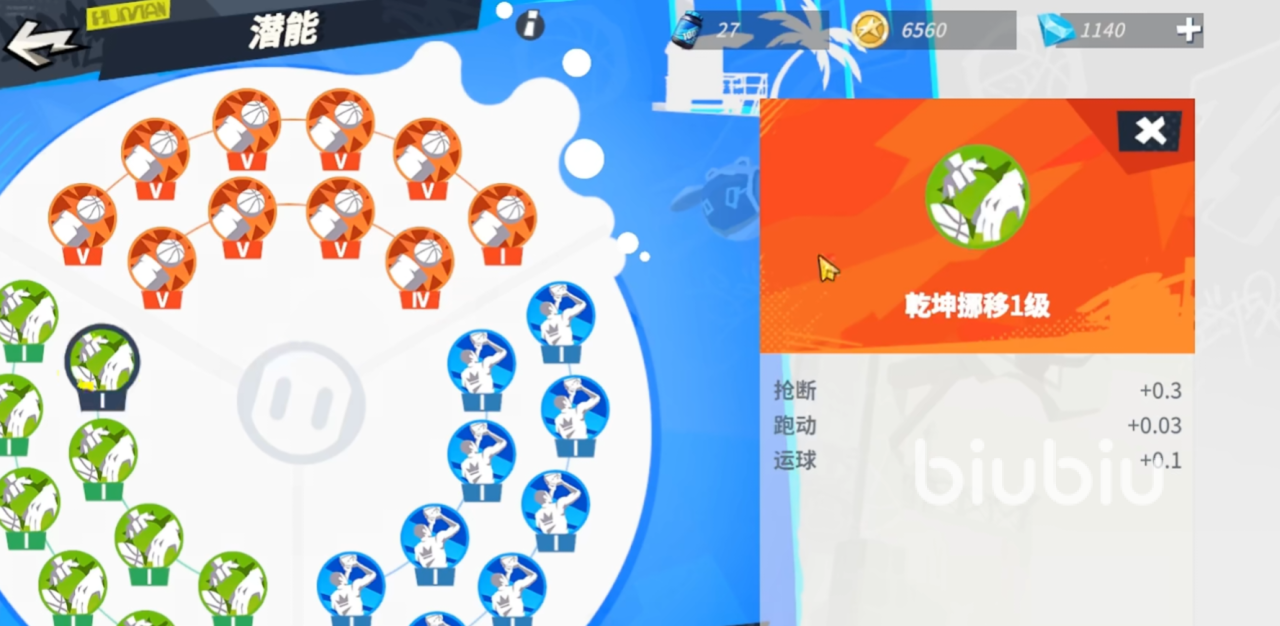
周长的绿色潜能则推荐佩戴乾坤挪移,这个潜能的选择其实没什么好说的,因为周长作为一个需要持续控球,拿球的球员,他的抢断能力一定是不能弱的,如果弱的话,那在团队对抗当中将会很被动。这个潜能也增加了他一点跑动能力,可以让周长在转场能力和移动能力都得到增强。
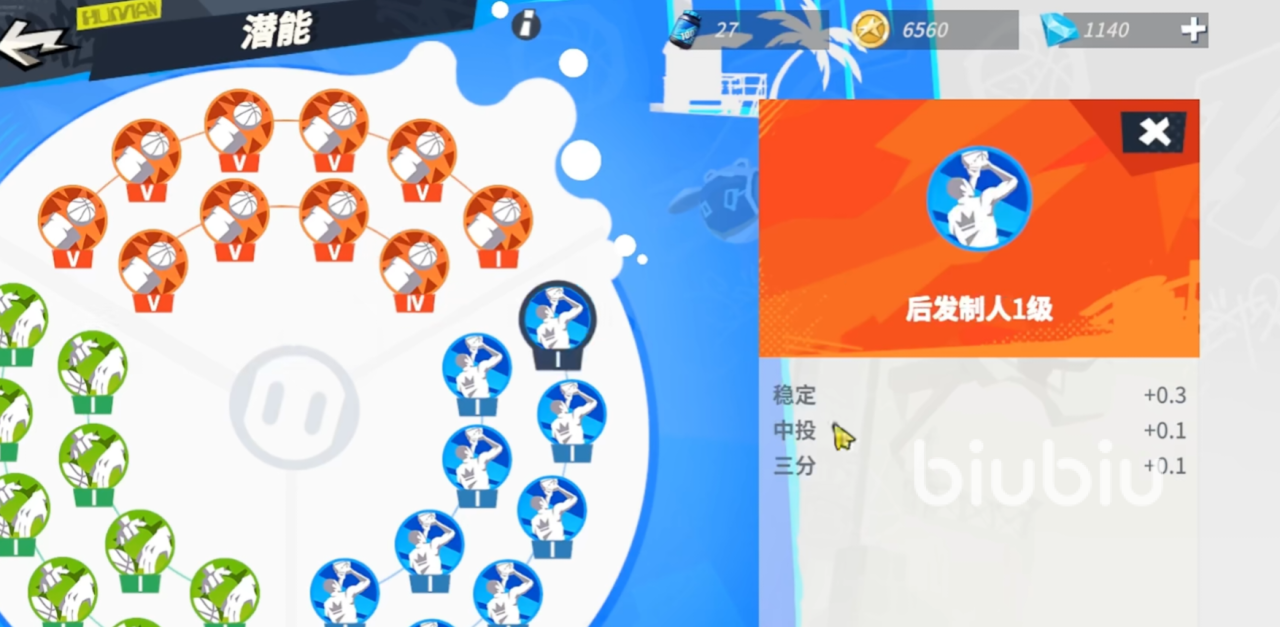
周长的蓝色潜能推荐佩戴后发制人。这个潜能会进一步的提升,周长的三分能力同时也弥补了,因为红色潜能不带火力覆盖,而缺少的一点稳定属性,同时后发之人也可以为周长增加他的中分能力,虽然周长不以中分著名,但中分作为一个篮球球员的基本功,周长这里也是必不可少的。
佩戴上述潜能,不仅可以将周长的属性发挥到最大化,同时也能弥补他的一些短板。在目前版本来说,这些也是最适合周长的潜能了。
好了,小编在本篇文章对全明星街球派对周长潜能展开了分析,其实在目前版本来说,周长他的单人作战能力和控场得分能力,是几乎罕逢敌手的,是非常推荐大家把他当做主力球员培养。
">全明星街球派对周长潜能该带什么 周长潜能攻略
蒂耶尔尼
第69届威尼斯电影节
北路梆子
DenuvOwO小组继续用他们的虚拟机管理程序攻破更多的游戏大作,这一次又有三款获得了更新。 
DenuvOwO攻破了最新版本的《赤色沙漠》(1.00.03)、《生化危机:安魂曲》(22277314)和《怪物猎人:荒野》(22195748)。现在这些游戏都拥有了最新版本的虚拟机管理程序,并符合CS.RIN社区对虚拟机所采用的安全标准。
目前尚不清楚该组织的后续计划,但截至目前,他们几乎已经更新了所有游戏的虚拟机攻破程序(仅剩《原子之心》《阿凡达:潘多拉边境》和《侏罗纪世界:进化3》尚未更新),因此DenuvOwO很可能很快就要开始新一轮的攻破行动了。
">DenuvOwO攻破《红色沙漠》、《生化危机9》等游戏最新D加密
圣米歇尔 (埃纳省)
露易絲·布瑞莉
Tiny-G


